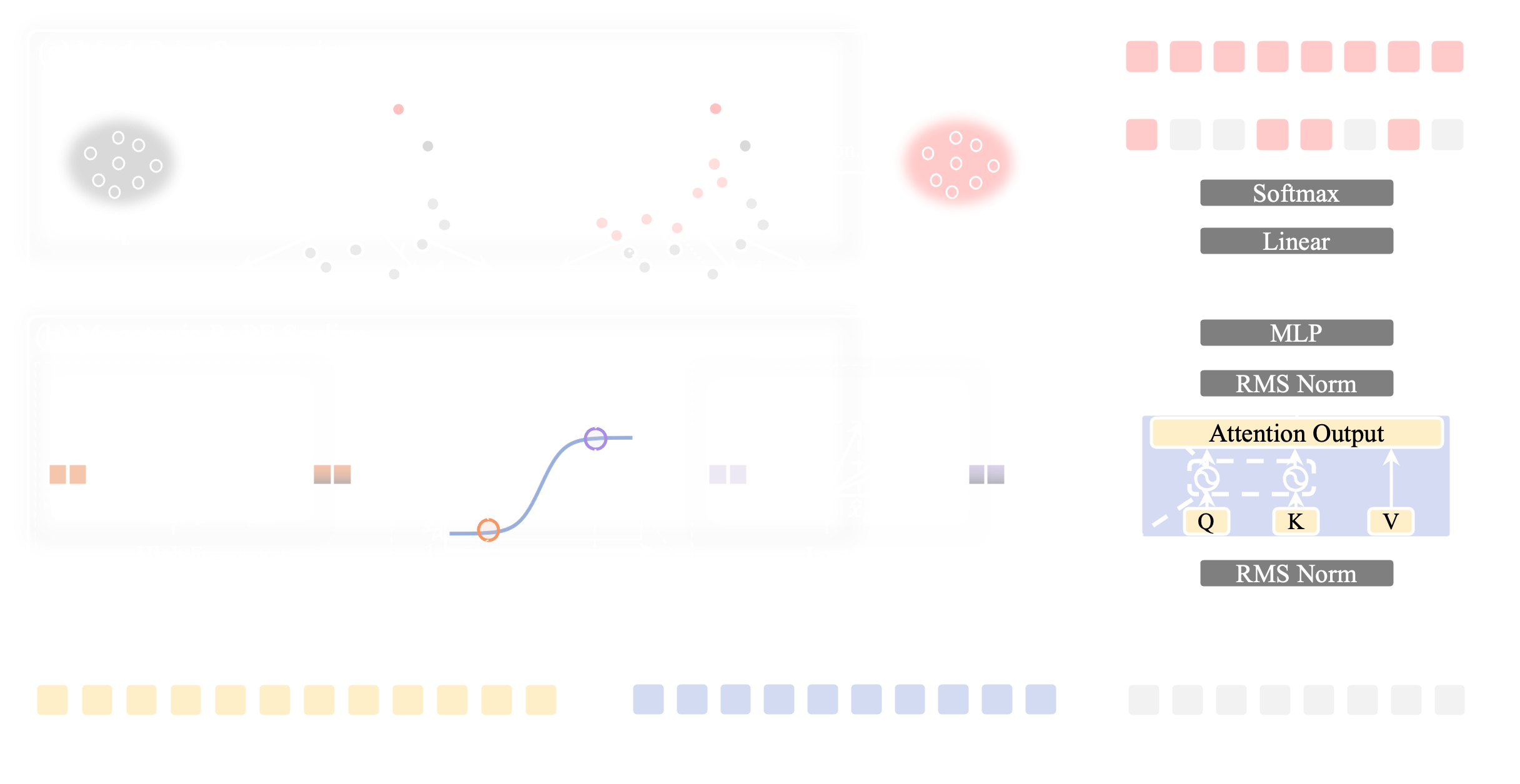
Where do LDVLMs fail?
Before fixing anything, we measure two concrete failure modes inside LLaDA-V and LaViDa: mask prior drift and positional attention collapse.
Hidden states drift toward a shared mask prior

Figure 2. (a) Fewer generation steps → lower distinct-n and higher repetition. (b) 3D PCA trajectories: vocab-mean and uncontextualized mask token converge in the final layer. (c) Contextualized mask tokens align with the vocab mean far more strongly than random embeddings.
Across generation steps, the hidden states of contextualized mask tokens are pulled toward the mean vocabulary direction in the final layer.
The fewer the unmasking steps, the stronger the collapse — and the more the model emits structured repetitions instead of diverse text.
This motivates Mask Prior Suppression: remove the prior direction from the final hidden state before the LM head.
Attention collapses onto nearby mask tokens
Generation tokens disproportionately attend to nearby mask tokens with little semantic content, while attention to distant visual tokens decays sharply with distance.
A frequency decomposition reveals the cause: high-frequency RoPE dimensions dominate at short range, low-frequency ones carry long-range interactions — but the overall attention to far visual tokens stays weak.
This motivates Monotonic RoPE Scaling: lift low-frequency components more strongly than high-frequency ones to restore long-range visual attention.
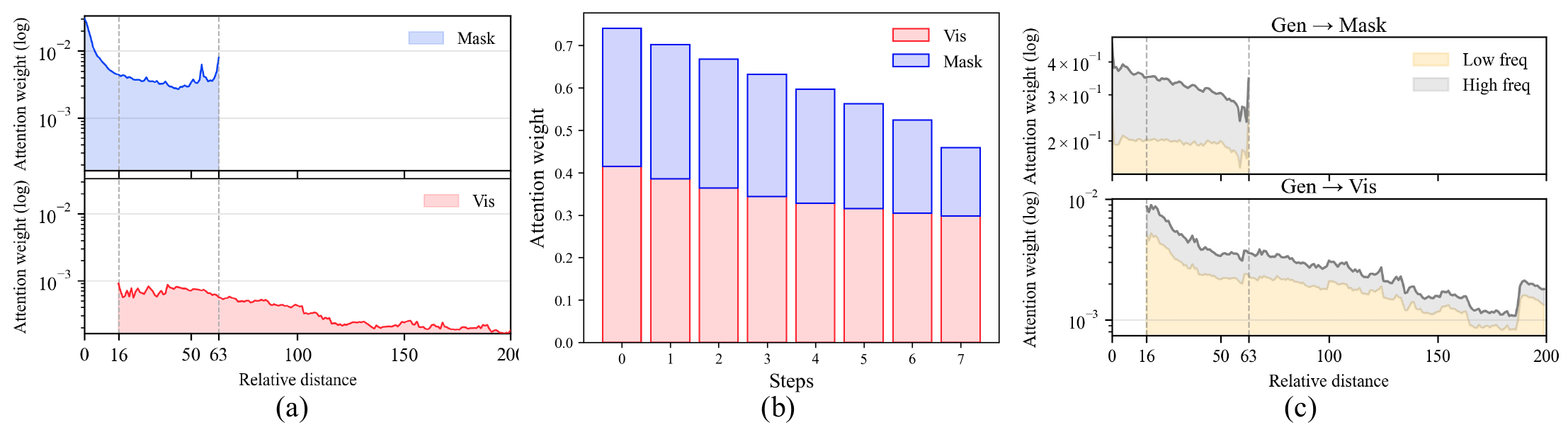
Figure 3. (a) Attention vs. relative distance — mask tokens are over-attended, visual tokens decay quickly. (b) Per-step attention summed over visual vs. mask tokens — mask tokens absorb comparable mass throughout decoding. (c) Frequency-wise decomposition: high-freq dominates short range, low-freq long range; overall long-range attention is still weak.